Understanding the Foundations: Probability Theory and Random Variables in Machine Learning
machine learning
Author
Riley Rudd
Published
October 16, 2023
Probability theory is the mathematical study of uncertainty, quantifying uncertainty about the world. It is important to understand as a basis to machine learning, because the design of learning algorithms often relies on probabilistic assumptions about the data. Probability theory allows algorithms to reason effectively in situations where there cannot be certainty.
Random Variables
Random variables are at the core of probability theory, they are a variable whose value is determined by the outcome of a random process. They can be discrete, taking a specific value from a finite set, or continuous, having any value in a range. In Machine learning, random variables often represent the input features, output predictions, or latent variables in the model.
Multiple views on Probability Theory
We can divide probability theory into two main branches:
Classical probability: based on equally likely outcomes in a sample space. As an example, when flipping a coin, the probability of getting either heads or tails is 1/2
Bayesian probability: The Bayesian view of probability contrasts frequentist probability in the sense that the latter relies on the existence of one best combination of parameters. The Bayesian probability treats parameters as random variables. Therefore, each parameter has its own probability distribution.
Applications in Machine Learning
Data Modeling: machine learning models often work by using data that has randomness/uncertainty. Random variables are used to quantify this uncertainty, allowing for the development of models.
Bayesian inference: Bayesian methods are used in machine learning for decision-making involving uncertainty. These methods leverage probability theory and random variables to update predictions when new data is available.
Classification: in classification models, where we assign data to specific categories, random variables can be used to represent the uncertainty with each class assignment.
Reinforcement learning: In reinforcement learning, an agent interacts with an environment to learn optimal actions – random variables are used to represent rewards and consequences, helping the user to make decisions under uncertain circumstances.
Probability Theory in Action
Let’s check out a hands-on example using a Gaussian Naive Bayes classifier. This probabilistic model is used for classification tasks and is based on Bayes’ theorem. This algorithm does well in predicting the correct class the features belong to, it considers the probability of occurrence of each class and assigns the label value to the class with the higher probability.
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import make_classificationfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score# Generate a synthetic datasetX, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, random_state=42)# Split the dataset into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=32)# Train a Gaussian Naive Bayes classifiermodel = GaussianNB()model.fit(X_train, y_train)# Make predictions on the test sety_pred = model.predict(X_test)# Calculate accuracyaccuracy = accuracy_score(y_test, y_pred)print(f'The Accuracy of Prediction is: {accuracy:.2f}')
The Accuracy of Prediction is: 0.85
In this code chunk, we’ve generated a synthetic data set, split it into a training and testing set, then trained a Gaussian Naive Bayes classifier instance on the data, and printing the accuracy of prediction.
Visualizing Probabilistic Predictions
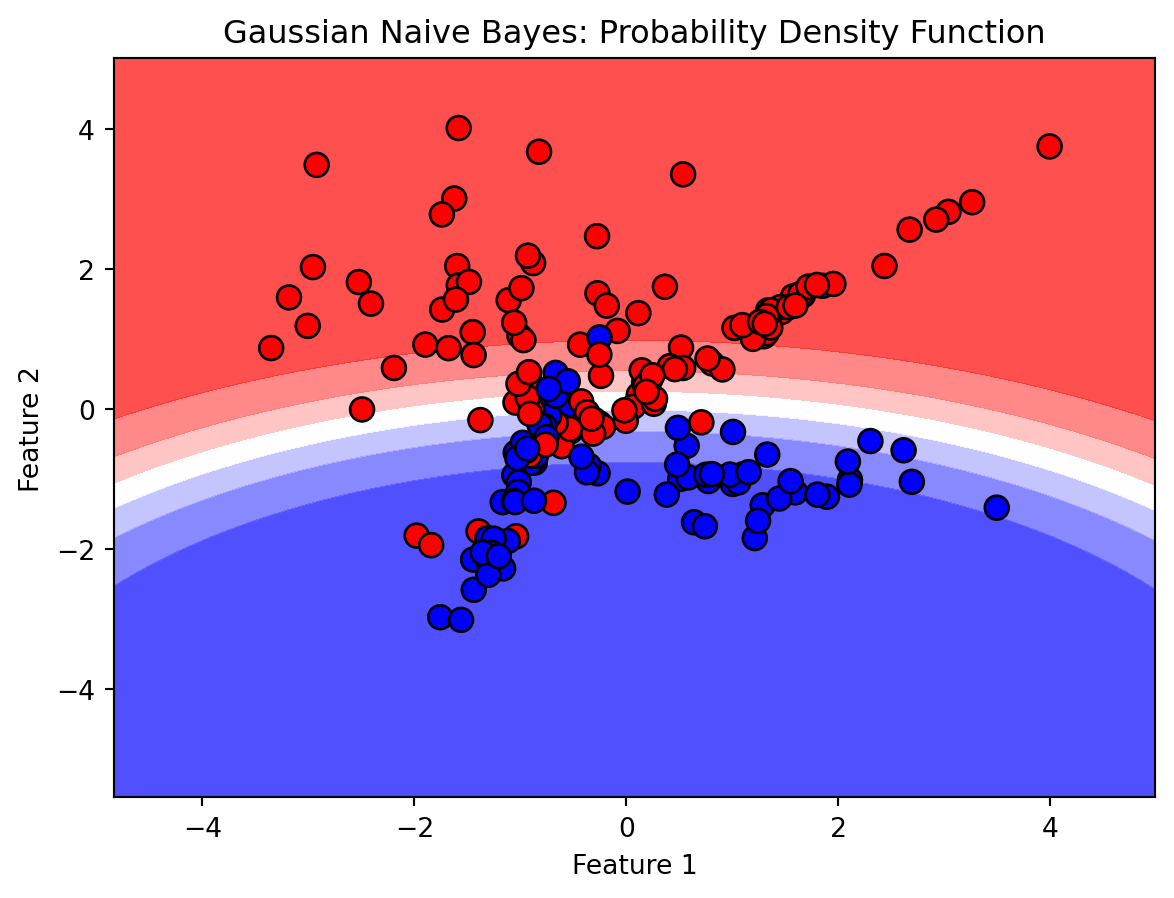
Now, let’s visualize the probabilistic natures of the Gaussian Naive Bayes predictions using a probability density function (PDF) plot.
In this visualization, decision regions are plotted based on probabilistic predictions of the model. The scatter plot shows the test set points, color-coded by true class labels.
Conclusion
Probability theory is not just a theoretical concept; it forms the backbone of practical machine learning applications. By understanding and leveraging probability theory, we can build models that provide not only predictions but also quantify the uncertainty associated with those predictions. The Gaussian Naive Bayes example showcased here is just one instance of how probability theory seamlessly integrates into machine learning workflows, allowing for robust and informed decision-making.