Unmasking Anomalies: A Deep Dive into Outlier Detection in Machine Learning
machine learning
Author
Riley Rudd
Published
December 6, 2023
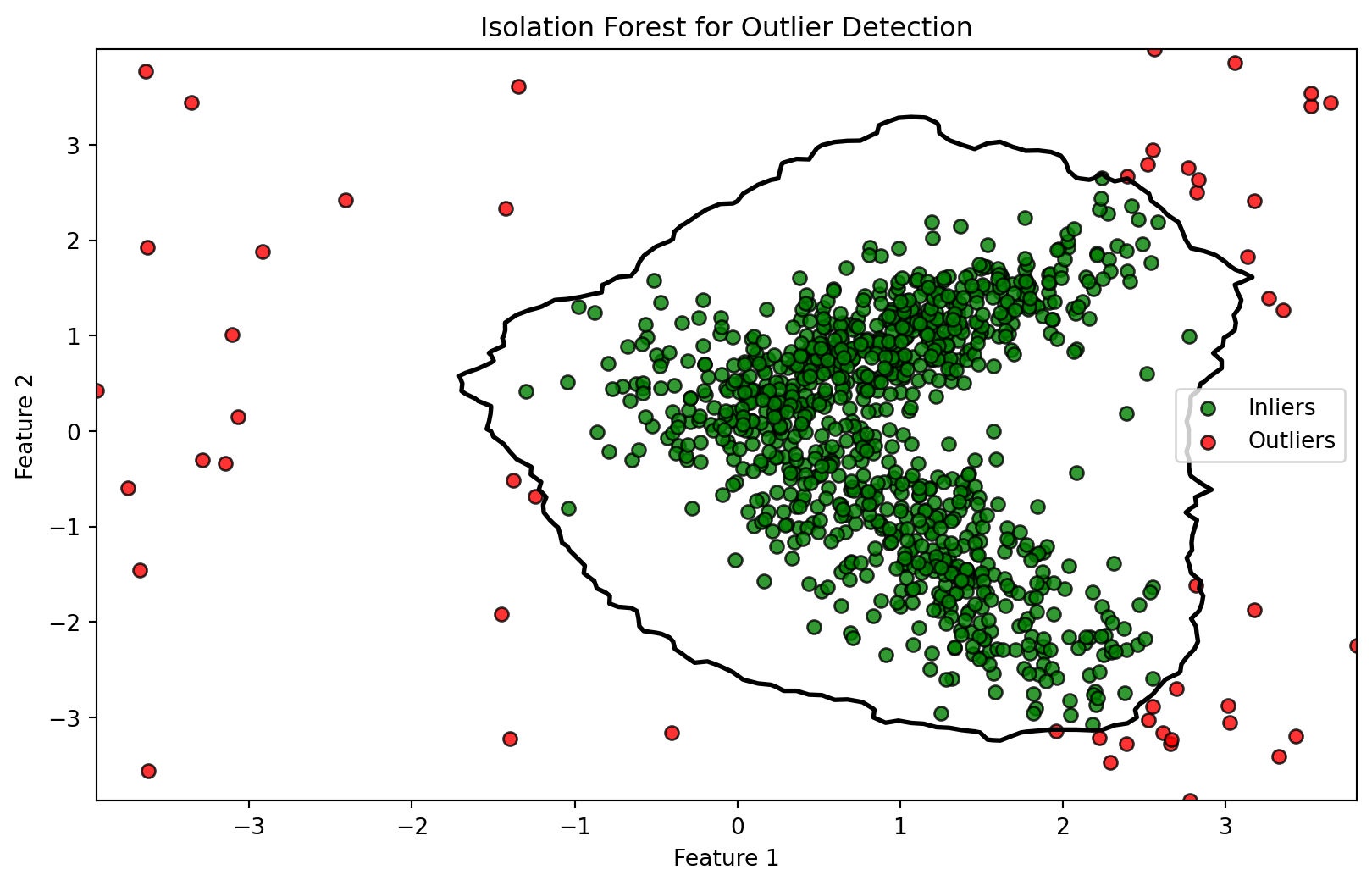
Anomalies, by definition, are data points that deviate significantly from the majority of the dataset. Detecting these outliers is crucial in fields such as fraud detection, network security, healthcare, and more. In this blog, we will explore the concept of anomaly detection, its significance, common techniques, and real-world applications. The goal of outlier detection is to separate a core of regular observations from those that are irregular.
Why Detect Outliers?
In Machine Learning, data cleaning and preprocessing are essential steps to understand your data. Running ML algorithms without removing outliers causes less effective and useful models. Sometimes, it is essential to understand the context of your dataset to differentiate between true outliers versus changing trends in your data.
Common Techniques for Anomaly Detection:
Statistical Methods: Statistical approaches involve setting thresholds based on mean, median, standard deviation, or other statistical measures. Data points deviating beyond these thresholds are considered anomalies.
Machine Learning Models: Supervised and unsupervised machine learning models, such as isolation forests, one-class SVM, and autoencoders, can be trained to distinguish between normal and anomalous data points.
Clustering Algorithms: Clustering techniques, like k-means, can identify outliers by assigning them to clusters with fewer data points.
Density-Based Methods: Algorithms like DBSCAN (Density-Based Spatial Clustering of Applications with Noise) identify outliers based on low-density regions in the data space.