Linear Regression in Machine Learning: Finding Predictive Relationships
machine learning
Author
Riley Rudd
Published
November 30, 2023
Linear regression, a statistical model, serves as a fundamental tool for comprehending the correlation between input and output numerical variables. This model becomes particularly relevant in machine learning scenarios where the aim is to predict one variable based on another. The core idea behind linear regression is to identify a linear relationship, essentially determining the slope of the line and the y-intercept.
Model Training and Fitting
To initiate the process, a training dataset comprising samples is employed. While it’s possible to manually calculate the linear regression equation, modern tools like scikit-learn's LinearRegression model offer efficient solutions. After fitting the model to the data, predicting the position of a new data point becomes a straightforward task using the predict function.
Benefits: Extension, Interpretability, Insight
Linear regression is not confined to single-variable scenarios. It seamlessly extends to accommodate datasets with multiple dimensions, providing a versatile solution for a variety of prediction tasks. One of the remarkable features of linear regression is its interpretability. A positive slope clearly indicates that as the input variable (x) increases, the output variable (y) also increases, providing straightforward insights into the relationship.
Model Complexity and Coefficients:
The complexity of a regression model is characterized by the number of coefficients it employs. A coefficient of zero signifies no influence of the corresponding input variable on the model, adding a layer of interpretability to the model.
Gradient Descent for Model Fitting:
Understanding how a machine learning model achieves a good fit involves the concept of Gradient Descent. This iterative process begins with random values for each coefficient. By calculating the sum of squared errors for each pair of inputs and outputs, the model’s coefficient predictions are updated to minimize the error. This cycle repeats until further improvement is deemed impossible.
Data Preparation for Optimal Results:
While not mandatory, adhering to certain guidelines enhances the performance of linear regression models. Ensuring a linear relationship in the data is crucial, sometimes requiring transformations like log transformations for exponential relationships. Additionally, the assumption of non-noisy input and output variables underscores the importance of cleaning data by removing outliers before model fitting.
In conclusion, linear regression stands as a powerful and interpret-able tool in the realm of machine learning, providing valuable insights into predictive relationships between variables.
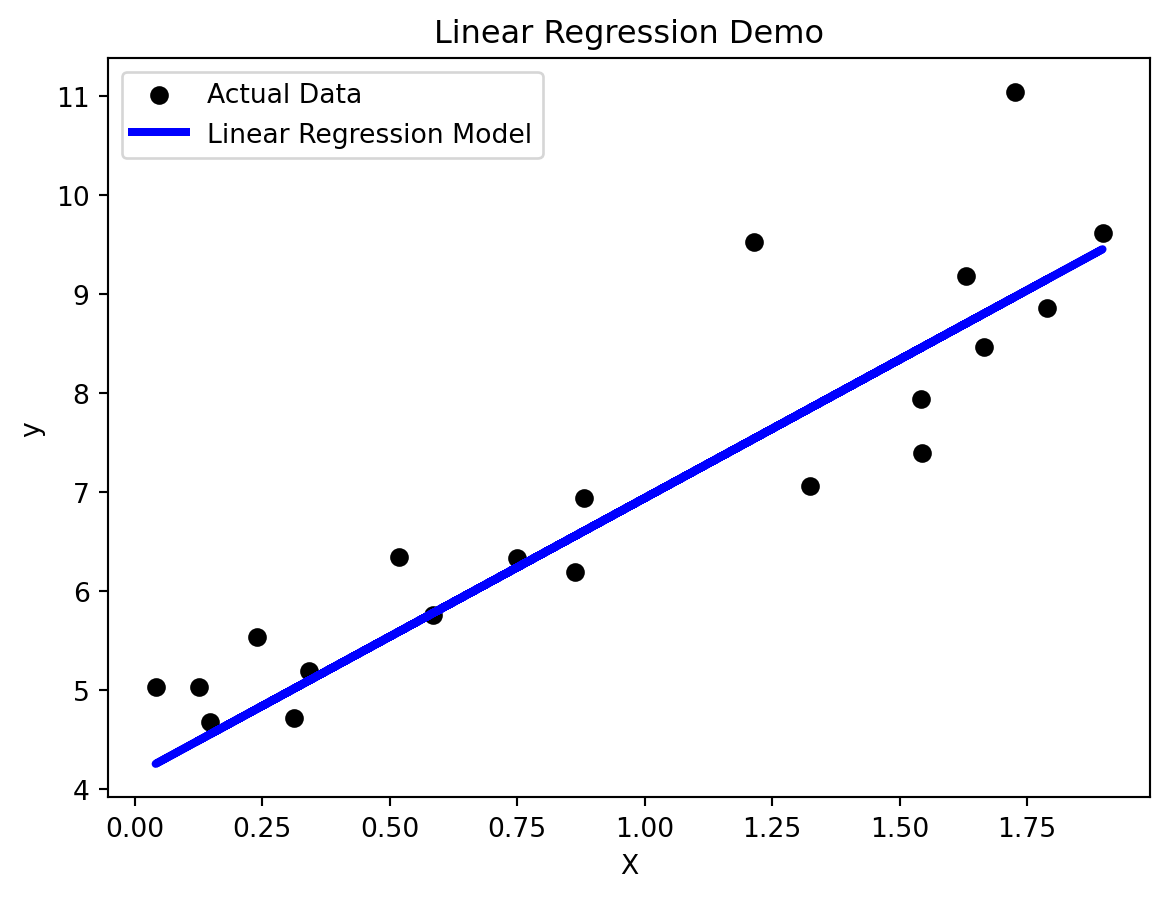
Visualizing Linear Regression
# Import necessary librariesimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_error# Generate synthetic datanp.random.seed(42)X =2* np.random.rand(100, 1) # Generate 100 random valuesy =4+3* X + np.random.randn(100, 1) # Linear relationship with some noise# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Create a Linear Regression modelmodel = LinearRegression()# Fit the model on the training datamodel.fit(X_train, y_train)# Make predictions on the test datay_pred = model.predict(X_test)# Visualize the resultsplt.scatter(X_test, y_test, color='black', label='Actual Data')plt.plot(X_test, y_pred, color='blue', linewidth=3, label='Linear Regression Model')plt.xlabel('X')plt.ylabel('y')plt.title('Linear Regression Demo')plt.legend()plt.show()# Evaluate the modelmse = mean_squared_error(y_test, y_pred)print(f"Mean Squared Error: {mse}")