Unveiling the Power of Clustering in Machine Learning
machine learning
Author
Riley Rudd
Published
November 15, 2023
Clustering is a type of unsupervised learning method, meaning conclusions are drawn about datasets without labeled responses. It is done by grouping a particular set of points based on their characteristics, aggregating them by their similarities. Clustering is generally used to find meaningful structure, underlying processes, and grouping inherent in a set of examples. Clustering can be thought of like organizing music by genre, something we all do naturally. By using clustering, you can learn something about your data previously unknown or invisible.
Why Use Clustering?
Real world examples are very complex and can be difficult to categorize. When you need to answer questions about this data, it is necessary to understand patterns within your data. Some patterns are easily visible to the eye, such as groups of height and weight points on a x and y axis. However, when there are many dimensions, it is impossible to visualize this on a 2D scale and therefore not possible to see by eye. Clustering can be useful in many industries. A few common examples include: anomaly detection, medical imaging, and market segmentation. Consider the example of using clustering for data compression. Replacing feature data for cluster ID will simplify the dataset and saves storage – which is a significant benefit when considering large datasets. This allows for faster and simpler training of machine learning models.
Clustering Methods
Density-Based methods: these methods consider the clusters as the dense region having some similarities and differences from lower dense region of the space. They have good accuracy and ability to merge clusters. One example is the Density-Based Spatial Clustering of Applications with Noise (DBScan). It is effective in identifying clusters of various shapes and sizes.
K-Means Clustering: this is one of the most popular clustering algorithms. It partitions the dataset into “k” clusters based on the mean values of data points. It iteratively assigns data points to clusters and recalculates the cluster until it converges.
Mean Shift: this is a non-parametric clustering algorithm that identifies dense regions in the data distribution. It iteratively shifts the center of cluster towards the modes of the data distribution.
Gaussian Mixture Models (GMM): These algorithms assumes the data is generated from a mixture of several Gaussian distributions, and models each cluster as a Gaussian distribution, assigning probabilities to data points belonging to each cluster.
Challenges with Clustering
Choosing the Right Number of Clusters: selecting the appropriate number of clusters can be challenging and considerably impact the results. There are analysis methods to help determine the optimal “k” clusters.
Sensitivity to Initial Conditions: some algorithms are sensitive to initial placement of centroids, requiring multiple initializations to obtain stable results.
Handling High-Dimensional Data: clustering high dimensional data can be complex, requiring dimensionality reduction techniques to improve the algorithm’s performance.
How is Clustering Achieved with DBSCAN?
To start, features in the dataset must all be numerically represented. If one of your features includes a “review” such as with ecommerce sites, you would need to define that review numerically, such as representing positive reviews with 0s and negative reviews with 1s. Then, the user will define a few parameters. One goal of clustering is to minimize inter-cluster similarity. This means that points in two different clusters should be as far apart (eg. different) as possible. The most important is determining the maximum distance between two points for one to be considered in the neighborhood of another. Another parameter is the minimum number of points in a neighborhood for a point to be considered a core point. If you choose a higher number, the resulting clusters will be more dense, and lower numbers result in clusters that are more sparse.
DBSCAN will then begin with a point to determine where the core points are, adding each core point into a cluster if they are in the same neighborhood. Then, it will add the non-core points, which are points in the same neighborhood as core points, but do not have enough members in the neighborhood to further extend the cluster. DBSCAN moves sequentially through each cluster until all points fall into a cluster or an outlier.
Deeper Dive into Clustering
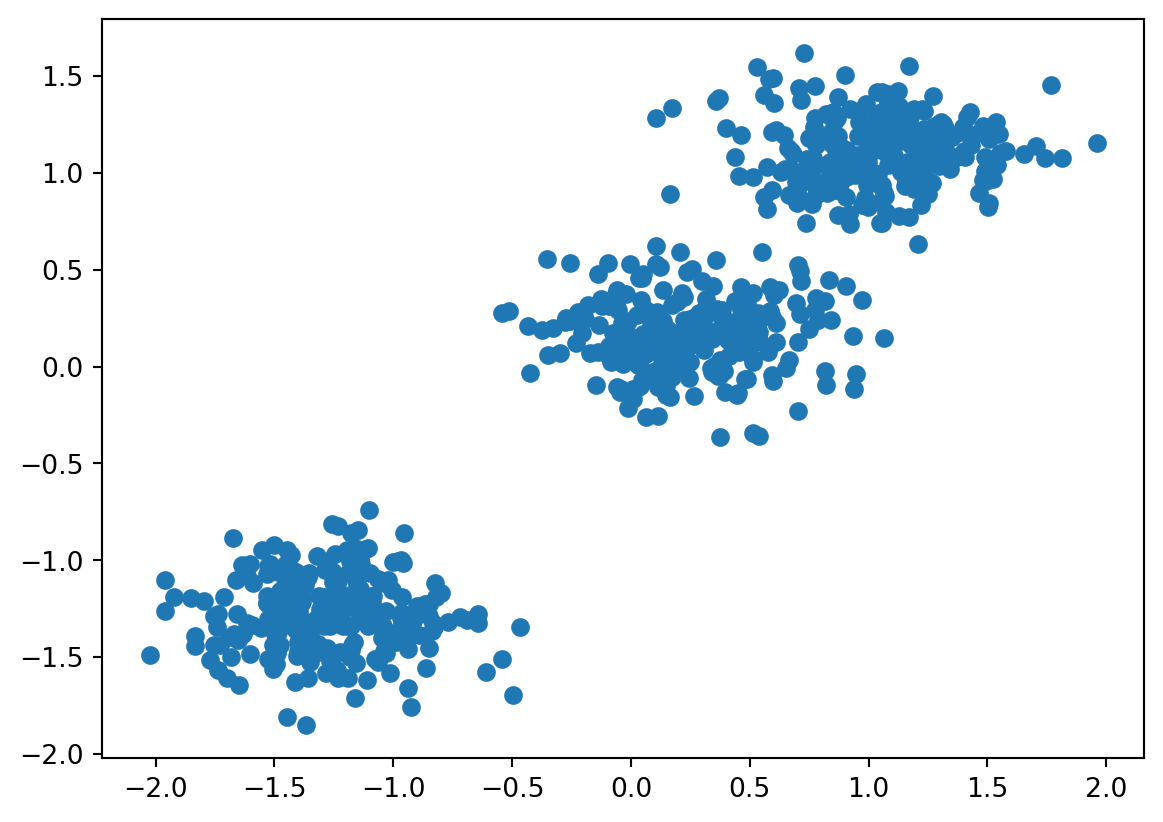
We can begin by creating a synthetic dataset that will look like 3 distinct blobs.
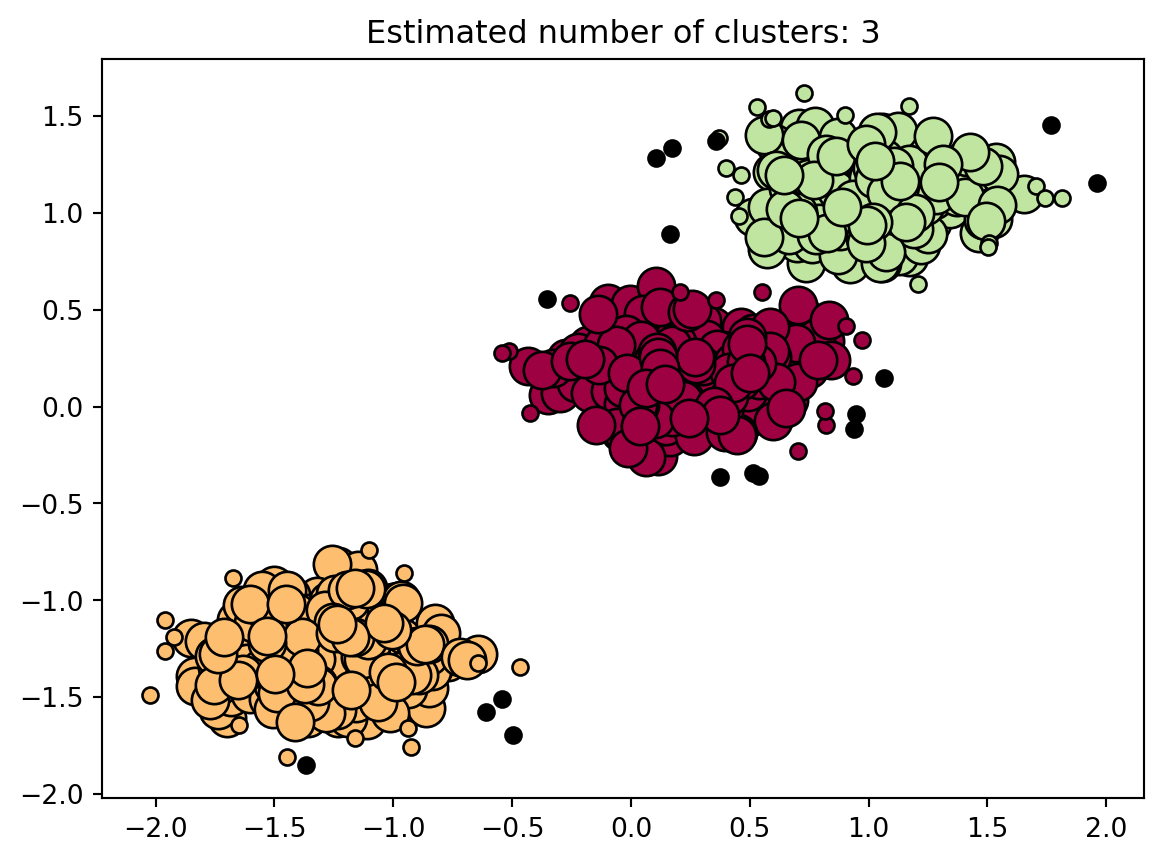
Next, we will compute DBSCAN, printing the number of clusters and noise points, and finally visualizing where DBSCAN has identified clusters. In the plot, core points are larger than non-core points and color coded according to cluster. Noise samples are in black.
import numpy as npfrom sklearn import metricsfrom sklearn.cluster import DBSCAN# computer DBSCANdb = DBSCAN(eps=0.2, min_samples=10).fit(X)labels = db.labels_# see how many clusters and noise pointsn_clusters =len(set(labels)) - (1if-1in labels else0)n_noise =list(labels).count(-1)print("Number of clusters: %d"% n_clusters)print("Number of noise points: %d"% n_noise)#visualize clusters unique_labels =set(labels)core_samples_mask = np.zeros_like(labels, dtype=bool)core_samples_mask[db.core_sample_indices_] =Truecolors = [plt.cm.Spectral(each) for each in np.linspace(0, 1, len(unique_labels))]for k, col inzip(unique_labels, colors):if k ==-1:# Black used for noise. col = [0, 0, 0, 1] class_member_mask = labels == k xy = X[class_member_mask & core_samples_mask] plt.plot( xy[:, 0], xy[:, 1],"o", markerfacecolor=tuple(col), markeredgecolor="k", markersize=14, ) xy = X[class_member_mask &~core_samples_mask] plt.plot( xy[:, 0], xy[:, 1],"o", markerfacecolor=tuple(col), markeredgecolor="k", markersize=6, )plt.title(f"Estimated number of clusters: {n_clusters}")plt.show()
Number of clusters: 3
Number of noise points: 17
In this example, the dataset is hypothetically assumed to be about geographical music preferences. If it were a real data set, it may have been geographical locations with other features such as tempo, energy level, and beat pattern. DBSCAN identifies clusters of data points that are dense and well connected. The parameters for DBSCAN are “eps” which defines the maximum distance between samples to be considered near another, and “min_samples” which sets the number of samples in a neighborhood for a data point to be considered a core point. Next, DBSCAN will begin with an arbitrary point and expand the cluster by adding nearby points if they are densely packed. It will continue until no more points can be added, therefore having formed the cluster. After this, DBSCAN assigns the cluster label to each point. Those outside of any cluster are labeled as noise or outliers.
References
Demo of DBSCAN clustering algorithm — scikit-learn 1.3.2 documentation